2024-07-22 04:36 点击次数:200

GPT-4o、Claude 3.5 Sonnet 等具有视觉能力的大语言模型(LLM),是否能像人类一样感知图像?
最新研究表明,在一套人类非常容易完成的 7 项视觉任务(比如两个圆是否重叠、两条线是否相交等)中,Claude 3.5 Sonnet 等四种最先进的视觉语言模型(VLM)的平均准确率只有 56.2%。它们似乎并不是在真正地“看”,而是在做有根据的猜测。
相关研究论文以“Vision language models are blind”为题,已发表在预印本网站 arXiv 上。
然而,这是否意味着这些“视觉” AI 模型毫无用处?远非如此。VLM 在识别诸如人类行为和表情、日常物品和情境的照片等方面都表现了出很高的准确性。
正如论文作者之一 Anh Totti Nguyen 所说:“‘盲目’对人类来说就有多种不同的定义,目前还没有一个词可以描述 AI 对我们展示的图像的这种盲目性,也没有技术能够准确地可视化模型看到的东西。它们的行为是输入文本提示、输入图像和数十亿权重的复杂函数。”
VLM 到底有多“瞎”?
研究团队通过 7 项简单任务测试了 VLM 的视觉能力,这些任务仅涉及 2D 几何基元(例如,线、圆和正方形),对人类而言,只需要极少的知识即可完成。他们测试了四个 SOTA VLM:GPT-4o、Gemini-1.5 Pro、Claude 3 Sonnet 和 Claude 3.5 Sonnet。
任务一 识别线的交叉点数量
在两个提示和三种线宽的情况下,所有 VLM 在这个简单任务上的表现都很差。最高准确率只有 77.33%(Claude 3.5 Sonnet)。当两个图之间的距离变窄时,VLM 的表现往往会变得更差。这表明 VLM 能够识别线图的整体趋势,但无法“放大”以看到精细的细节。
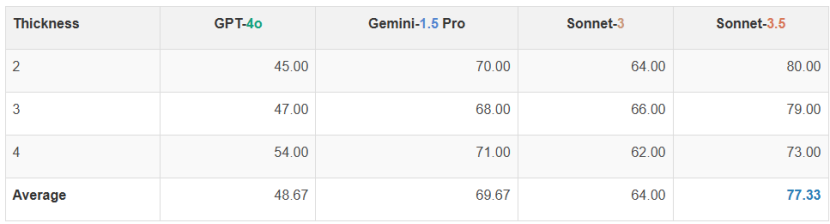
图 | 四种模型在计算线的交叉点任务上的性能
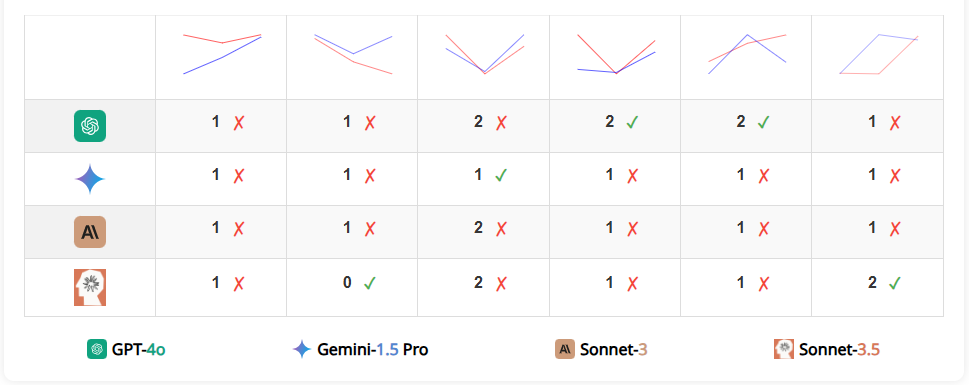
图 | VLM 不能可靠地计算线的交叉点。
任务二 识别两个圆是否重叠
即使圆对于人类来说很大且清晰可见,也没有任何 VLM 能够完美解决这个问题。所有图像和提示下的最高准确率为 92.78%(Gemini-1.5)。一个常见的趋势是,当两个圆靠得很近时,VLM 的表现往往较差。这表明VLM的视觉似乎还不够清晰,无法看到两个圆之间的细微间隙或交点。
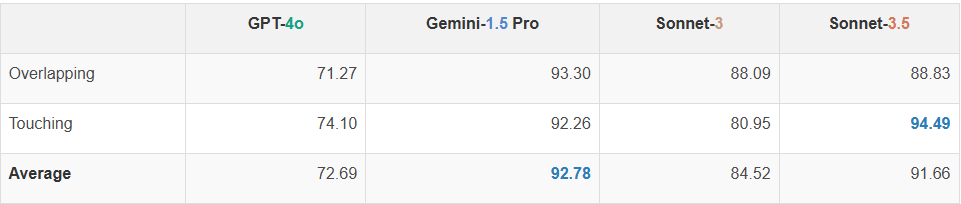
图 | 四种模型在圆圈重叠任务上的性能

图 | 距离越小,VLM 越可能判断失败。
任务三 识别被圈起来的字母
尽管有一个红色椭圆叠加在上面,所有 VLM 仍然能够准确地拼写出字符串。然而,读出哪个字母被圈出来对所有 VLM 来说竟然是一个挑战。犯错误时,VLM 经常给出的结果是被圈出字母旁边的字母。有时模型会产生幻觉,给出该词中不存在的字符(例如“9”、“n”、“©”)。
除了 GPT-4o 之外,所有模型在两个英语单词上的表现比随机字符串略好,这表明知道单词可能有助于 VLM 做出更好的有根据的猜测,从而略微提高准确度。Gemini-1.5 和 Claude 3.5 Sonnet 得分较高,分别为 92.81% 和 89.22%,比 GPT-4o 和 Claude 3 Sonnet 的准确率高出近 20 个百分点。
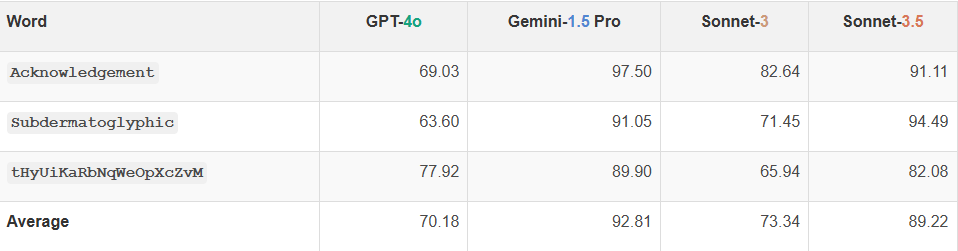
图 | 四种模型在识别圈出的字母任务上的性能
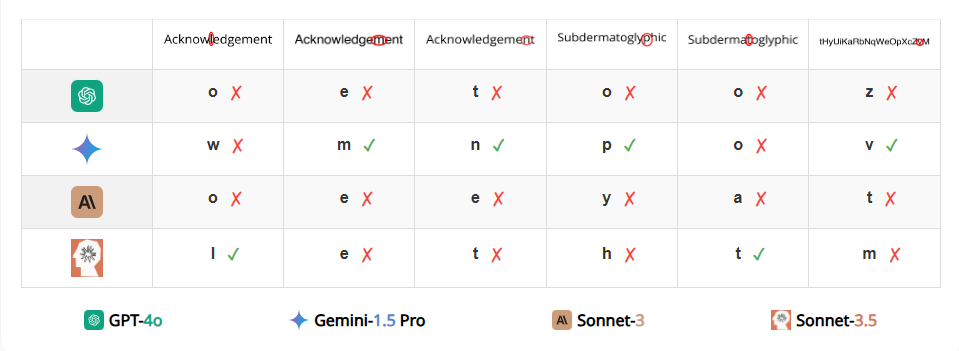
图 | 当犯错误时,VLM 倾向于预测与圈出的字母相邻的字母。
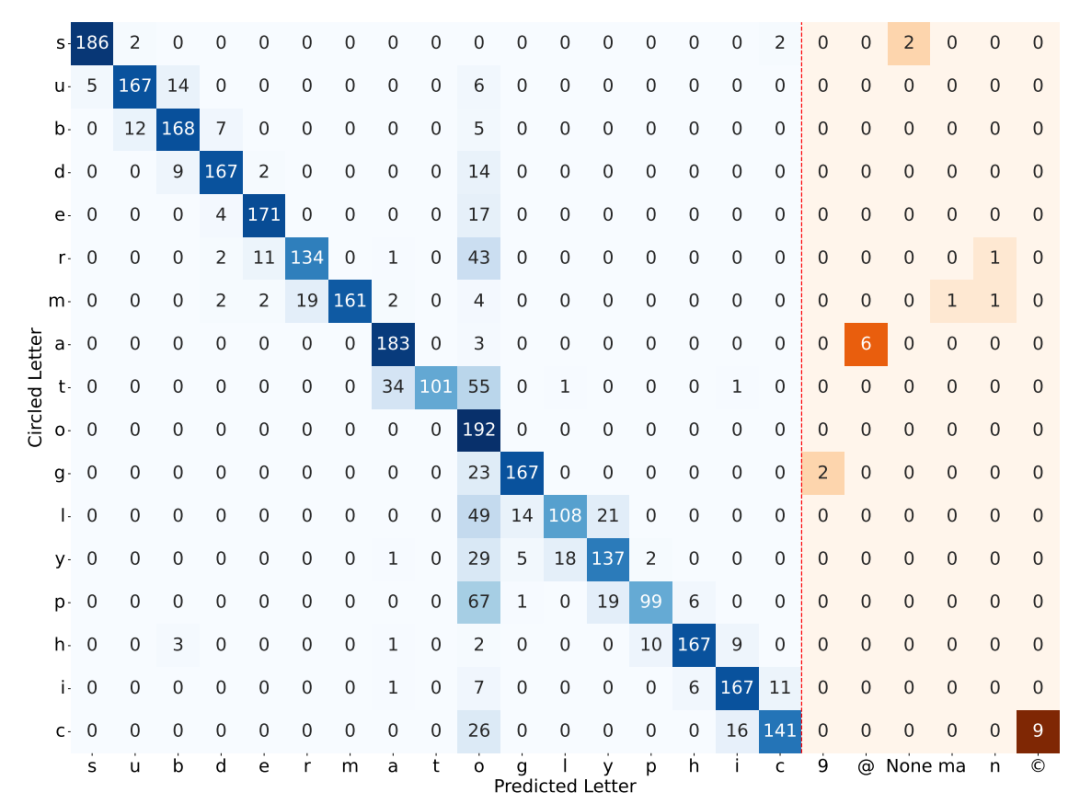
图 | 模型会产生幻觉,给出该词中不存在的字符(例如“9”、“n”、“©”)。
任务四 识别重叠形状的数量
无论形状是重叠的还是嵌套的,这两种情况似乎都对 VLM 构成了挑战。在计数重叠的圆和五边形的任务上,Claude 3.5 Sonnet 的表现比其他模型好得多(例如,75.83% 对应 Gemini-1.5的 9.16%)。当圆环数量超过五个且 VLM 预测的数量不正确时,Gemini-1.5 有 98.95% 的时间预测为“5”,而不管实际圆环的数量是多少。对于其他模型,这种情况的发生频率也比五边形的情况要高得多。这是因为它们都在训练数据中显著地包含了五个圆环的图像:奥运会环标志。这个标志在训练数据中重复出现,所以它们倾向于猜测“5”。

图 | 四种模型在识别重叠的圆圈/五边形数量上的性能
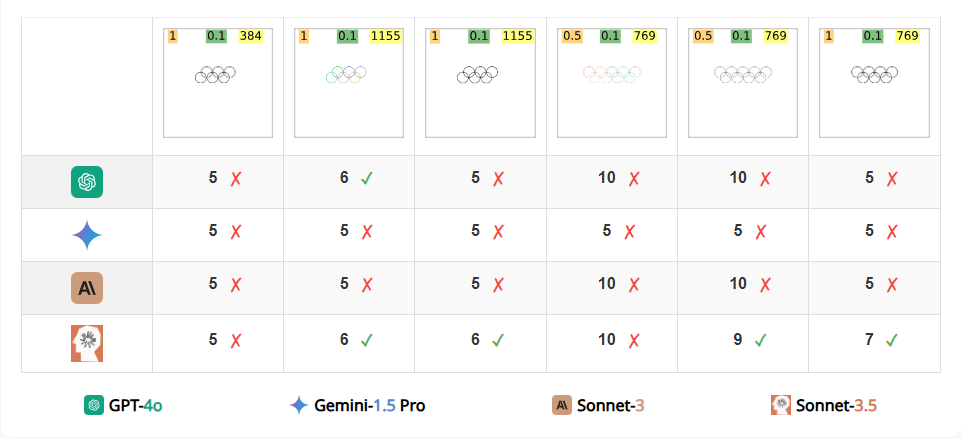
图 | 无论圆的颜色、线宽和分辨率如何,VLM 都不容易计数重叠的圆。
任务五 识别嵌套的正方形数量
GPT-4o 和 Claude 3 Sonnet 在计数两个或三个嵌套正方形时仍显得吃力。当计数增加到四个和五个时,所有模型的准确性都远低于 100%。结果显示,即使形状的边缘不交叉,VLM 提取形状的精确表示也并非易事。

图 | 四种模型在识别嵌套方形数量任务上的性能
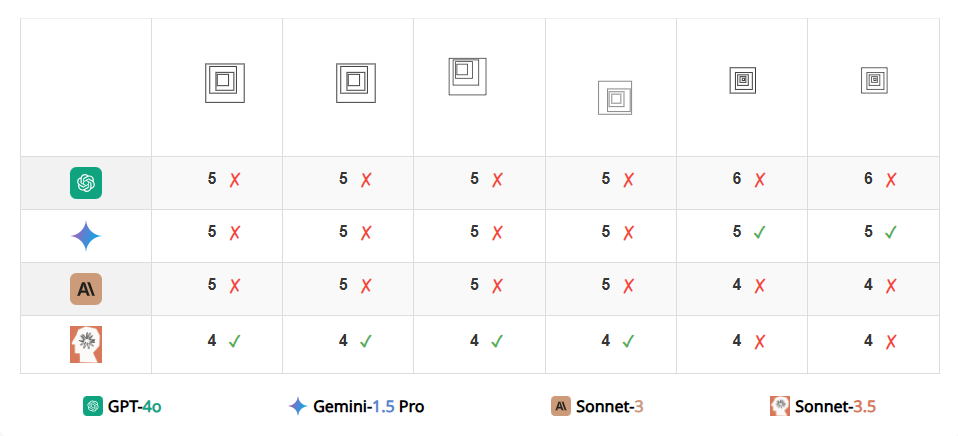
图 | 只有 Claude 3.5 Sonnet能数出大多数图像中的正方形。
任务六 识别网格的行和列的数量
VLM 难以准确计算空网格中的行数和列数。具体来说,它们的计数通常会偏差 1 或 2。这一发现表明,VLM 不能清晰地看到表格的每个单元格。有趣的是,研究团队在尝试通过在每个单元格中添加一个单词来简化任务后,观察到所有VLMs的准确性都有显著提高(例如,GPT-4o 从 26.13% 提高到 53.03%)。然而,没有任何模型能够完美解决这个任务,即使是最优秀的模型(Claude 3.5 Sonnet)在包含文本的网格上表现最佳,准确率为 88.68%,而在空网格上的准确率仅为 59.84%。
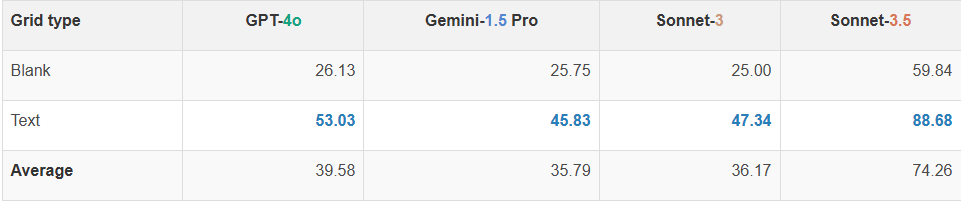
图 | 四种模型在计算网格中的行和列时的性能
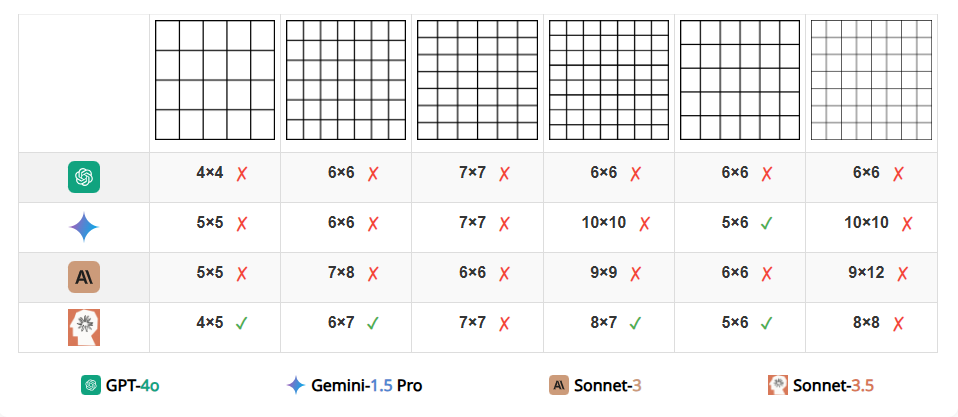
图 | 示例表明,模型在计算空白网格的行和列时大都失败。
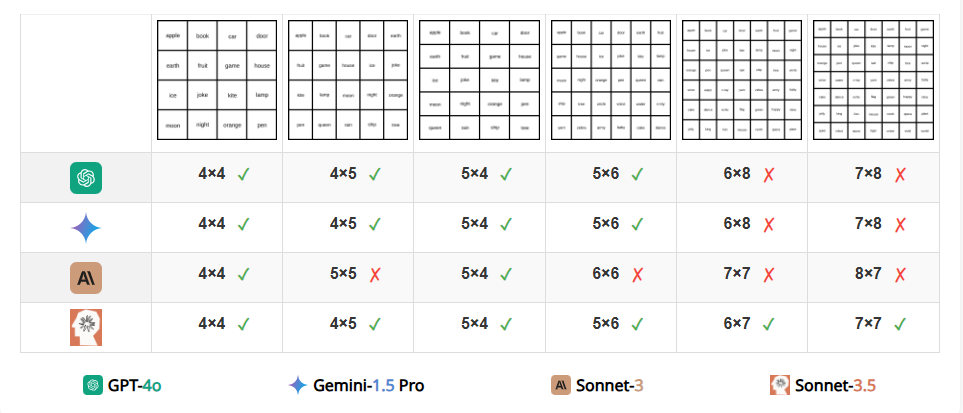
图 | 当文本包含在网格单元中时,所有 VLM 的性能都得到了提高,尤其是Claude 3.5 Sonnet。
任务七 识别站点间单色路径的数量
结果表明即使在两个站点之间只有一条路径的情况下,也没有模型能够达到100% 的准确性(最高的是 Claude 3.5 Sonnet,达到 95%;最差的准确率为23.75%)。VLM 的预测通常偏差 1 到 3 条路径。随着地图复杂性的增加,从 1 条路径增加到 3 条路径,大多数 VLM 的表现变得更差。
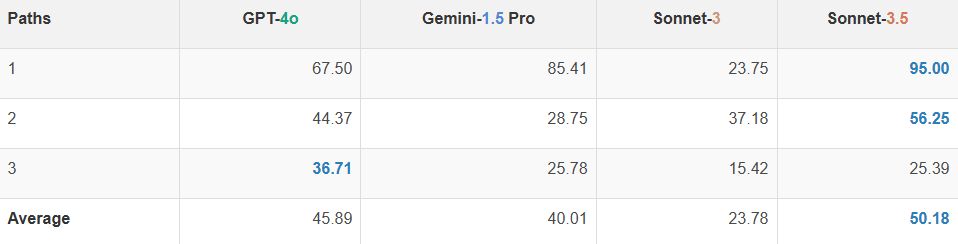
图 | 四种模型在站点间单色路径计数任务上的性能。

图 | 一些 VLM (Gemini-1.5, Claude 3 Sonnet)甚至在非常简单的情况下也会失败。随着路径数量的增加,VLM 的性能往往会变差。
早期融合或是未来发展方向
实验结果表明,即使是最佳的 VLM 仍然在努力解决一个五岁小孩都能轻易解决的问题。这些限制可能很大程度上是由于将视觉整合到 LLM 中的晚期融合(late-fusion)方法,而早期融合(early-fusion)可能是未来的发展方向,即将视觉编码器与语言模型在更早的阶段融合,例如在 token embedding 阶段或视觉特征提取阶段进行融合。
此外,研究团队还发现,简单地使用 LORA 在提出的任务上微调一个 7B 参数的、最先进的晚期融合开源 VLM,并不能得到一个高性能的模型。也就是说,训练一个在 BlindTest 上表现良好的单一模型可能是一个有趣的未来研究方向。